Wie GPT3 funktioniert - Visualisierungen und Animationen
Jul 27, 2020 • Arne VogelDies ist eine Übersetzung des Beitrags “How GPT3 Works - Visualizations and Animations” von Alammar, Jay (2020), abgerufen von: https://jalammar.github.io/how-gpt3-works-visualizations-animations/
Ein trainiertes Sprachmodell erzeugt Text.
Wir können ihm optional etwas Text als Eingabe übergeben, was seine Ausgabe beeinflusst.
Die Ausgabe wird aus dem erzeugt, was das Modell während der Trainingsphase “gelernt” hat, in der es riesige Textmengen gescannt hat.
Training ist der Prozess, bei dem das Modell viel Text vermittelt wird. Es wird einmal gemacht und ist abgeschlossen. Alle Experimente, die wir hier sehen, sind von diesem einen trainierten Modell. Es wird geschätzt, dass das Training 355 GPU-Jahre und 4,6 Millionen Dollar gekostet hat.
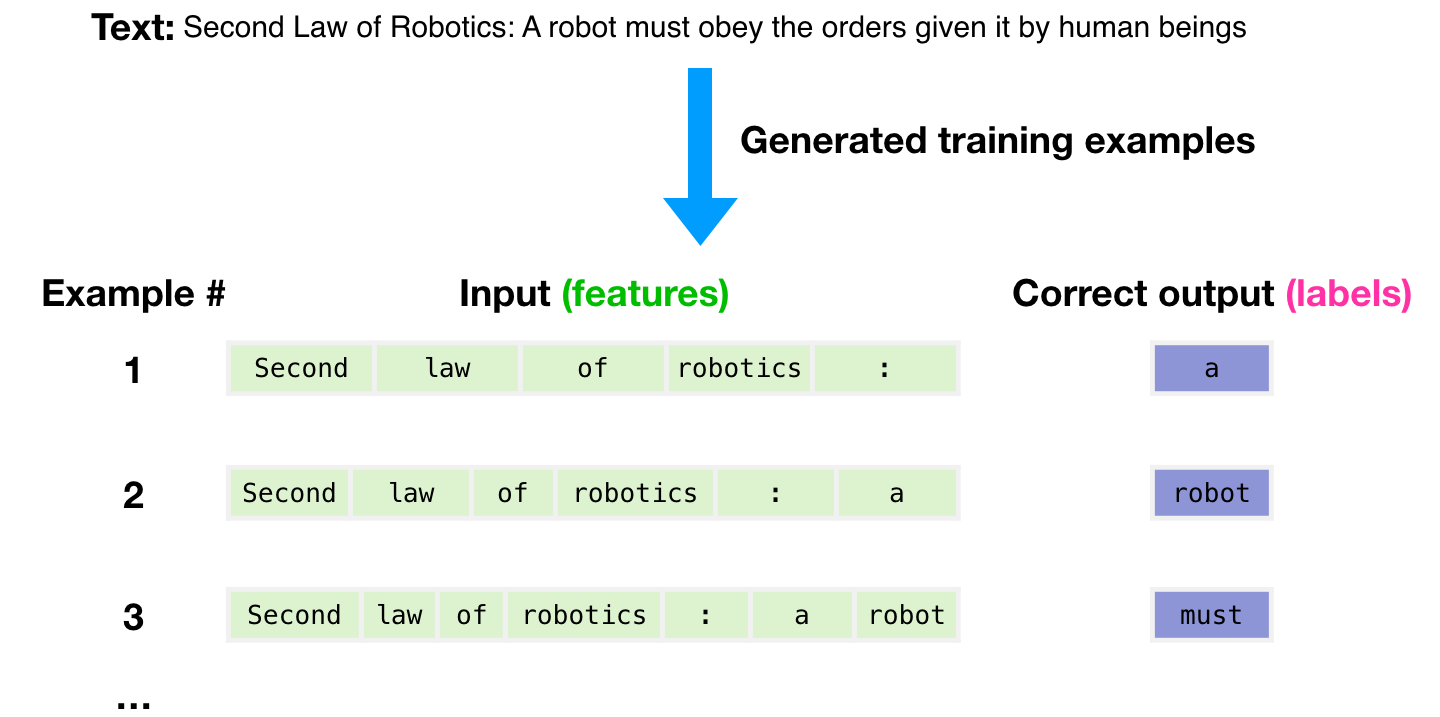
Ein Datensatz von 300 Milliarden Textmarken wurde verwendet, um Trainingsbeispiele für das Modell zu generieren. Dabei handelt es sich beispielsweise um drei Trainingsbeispiele, die aus dem Satz oben generiert werden.
Man sieht, wie Sie ein Teilfenster über den gesamten Text schieben und viele Beispiele erstellen können.
Dem Modell wird ein Beispiel vorgelegt. Wir zeigen ihm nur die Features und er soll das nächste Wort vorhersagen.
Die Vorhersage des Modells wird falsch sein. Wir berechnen den Fehler in seiner Vorhersage und aktualisieren das Modell, damit es beim nächsten Mal eine bessere Vorhersage macht.
Dies wird millionen Mal wiederholt.
Lassen Sie uns nun diese Schritte etwas genauer unter die Lupe nehmen.
GPT3 erzeugt die Ausgabe Token für Token (wir nehmen an, ein Token ist vorerst ein Wort).
Bitte beachten Sie: Dies ist eine Beschreibung, wie GPT-3 funktioniert, und keine Diskussion darüber, was daran neu ist (was vor allem der unglaublich große Maßstab ist). Die Architektur ist ein Transformator-Decoder-Modell, das auf diesem Papier basiert https://arxiv.org/pdf/1801.10198.pdf
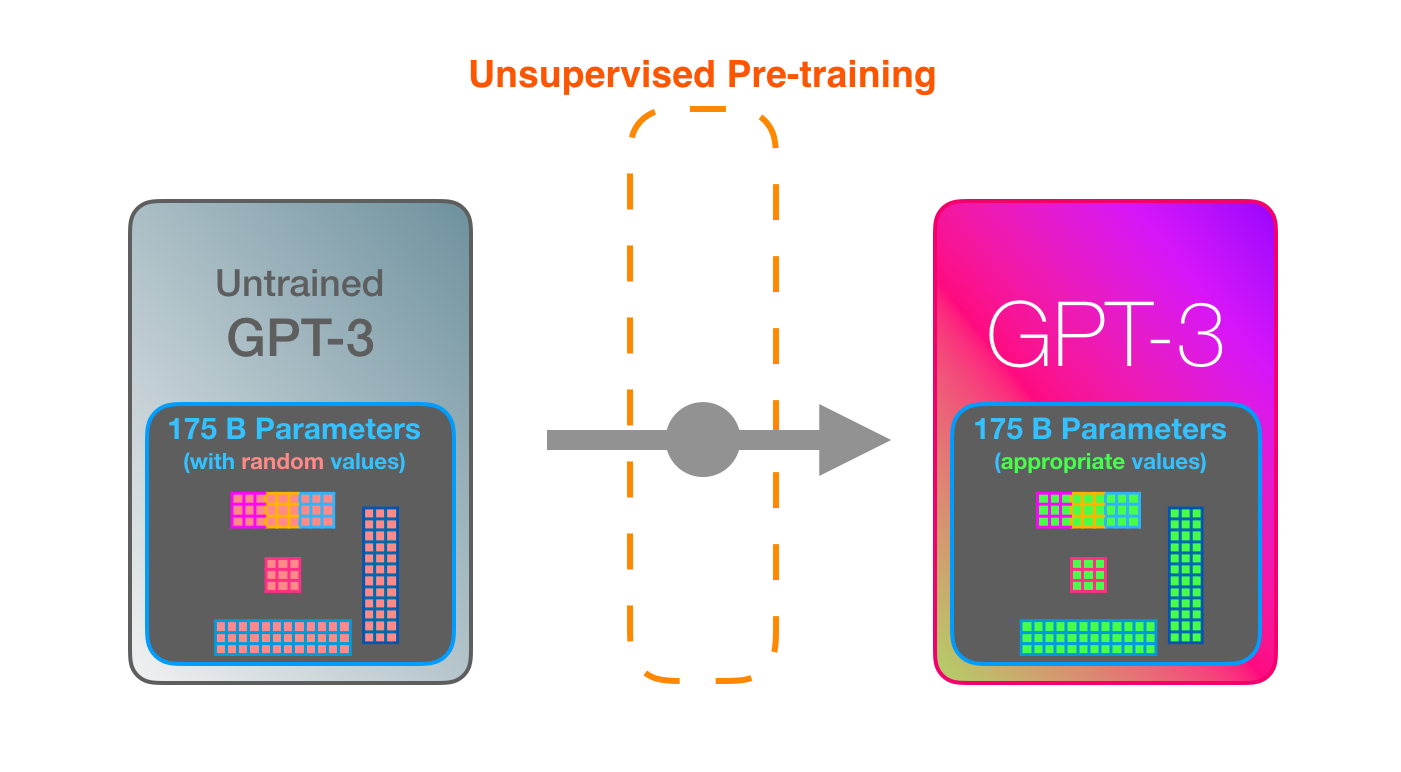
GPT3 ist MASSIV. Es kodiert das, was es aus dem Training lernt, in 175 Milliarden Zahlen (genannt Parameter). Diese Zahlen werden verwendet, um zu berechnen, welches Token bei jedem Durchlauf erzeugt werden soll.
Das untrainierte Modell beginnt mit Zufallsparametern. Beim Training werden bessere Werte gesucht, die zu besseren Vorhersagen führen.
Diese Zahlen sind Teil von Hunderten von Matrizen innerhalb des Modells. Die Vorhersage besteht hauptsächlich aus einer Vielzahl von Matrizenmultiplikationen.
Um Licht darauf zu werfen, wie diese Parameter verteilt und verwendet werden, müssen wir das Modell öffnen und hineinschauen.
GPT3 ist 2048 Tokens breit. Das ist sein “Kontextfenster”. Das heißt, es hat 2048 Pfade, auf denen die Token verarbeitet werden.
Folgen wir der violetten Spur. Wie verarbeitet ein System das Wort “Robotik” und produziert “A”?
Übersicht der Schritte:
- Das Wort in einen Vektor (Liste von Zahlen) umwandeln, der das Wort repräsentiert
- Vorhersage berechnen
- Ergebnisvektor in ein Wort umwandeln
Die wichtigen Berechnungen des GPT3 erfolgen innerhalb seines Stapels von 96 Transformator-Decoderschichten.
Dies ist das “Deep” beim “Deeplearning”.
Jede dieser Schichten hat ihren eigenen 1,8 Milliarden-Parameter, um ihre Berechnungen durchzuführen.
Dies ist ein Ausschnitt einer Eingabe und Antwort (“Okay human”) innerhalb von GPT3. Man erkennt, wie jedes Token durch den gesamten Schichtenstapel fließt. Die Ausgabe der ersten Wörter ist uns egal. Wenn die Eingabe beendet ist, kümmern wir uns um die Ausgabe. Wir speisen jedes Wort zurück in das Modell ein.
Im Beispiel der Codegenerierung von React (https://twitter.com/sharifshameem/status/1284421499915403264) wäre die Beschreibung die Eingabeaufforderung (in grün), zusätzlich zu ein paar Beispielen für Beschreibung => Code. Und der React-Code würde wie die rosa Token hier Token für Token generiert.
Ich gehe davon aus, dass die Priming-Beispiele und die Beschreibung als Eingabe angehängt werden, wobei spezifische Token die Beispiele und die Ergebnisse trennen. Dann werden sie in das Modell eingegeben.
Es ist beeindruckend, dass dies so funktioniert. Denn man wartet einfach ab, bis das Feintuning für GPT3 ausgerollt wird. Die Möglichkeiten werden noch erstaunlicher sein.
Durch die Feinabstimmung werden die Gewichte des Modells aktualisiert, um das Modell bei einer bestimmten Aufgabe besser zu machen.